
こんにちは。
オープンソースを活用しながら、低コストでエッジ デバイスやさらに小さなIoT デバイスで使用できる小さな AI モデルを作成する、駐車場AI R&D チャレンジの3回目です。
作成したPOCには大きく3つの課題がありました。どのような対策を施し克服したのかご紹介します。
データ注釈の課題克服
まず、時間のかかるプロセスである、データ注釈(アノテーション)の課題解決です。
利用可能なオープンソースの注釈ツールはいくつかありますが、今回のPOCの目的「AI モデルのトレーニングに使用される”ビットマップ マスク イメージを生成する”」こと。この 要件に一致するものはありませんでしたので、私はPython で OpenCV API を使用し自ら注釈モデルを作成しました。
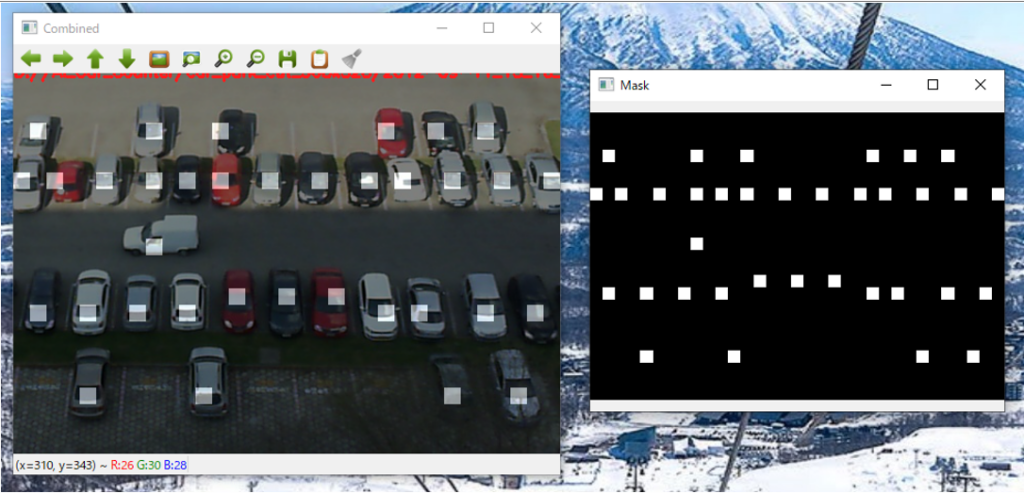
このアプリケーション製作は慣れていれば非常に簡単です。アプリケーションは 2 つのウィンドウで構成されています。 左側が入力画像、右側が出力マスクです。
ユーザーの作業は基本的に、
「車の位置にある左側の画像をクリック」する、
たったこれだけです。 これにより、右側のマスクが自動的に更新されます。
ちなみに同じ場所をもう一度クリックすると削除できます。キーコントロールで画像を保存、次の画像を選択、ポイント設定という流れでザクザクと設定を進められます。 (すべての画像が同じディレクトリにあると想定ですが)
簡単とはいえども、画像数が多いと当然ながら非常に時間がかかります。もっと楽をしたいので私は、手動で1,000 枚の画像に注釈を付けた後で、その注釈付きの画像を活用して注釈付けAIのトレーニングと AI モデルを作成しました。
このトレーニング済みの AI モデルを使用して、残りの画像に注釈を付け作業を簡略化できました。
そもそもの元画像にミスが多かったせいで、手動で手直しも発生しましたが、とはいえゼロから画像に注釈を付けるよりもはるかに高速で処理できました。
AIモデルの課題克服
次に、注釈モデルアプリの中のAIモデルですが、IoT環境で使うため、プログラムサイズの軽量化が必要です。

私の製作した注釈モデルアプリのAI モデル(上図中央)は以下の 2 つの部分で構成されています。
- 前工程:事前学習された Mobilenet バックボーン (モデルの一部のみ)
- 後工程:カスタム FCNN (完全畳み込みネットワーク)
学習データ セットが小さかったため、私はこのアプローチを採用しました。 本AI モデルでは、小さなカスタム FCNN セクションのみがトレーニングされますので効率的です。 前工程のMobilenet は事前にトレーニングされているため、画像内の多くの低レベルの特徴を検出できます。後工程の カスタム FCNN のほうは、前工程のMobilenetの検出後画像をさらにフィルタリングし、車のみが検出できるようにしました。この結果私の製作した AI モデルのプログラムサイズは、float32 パラメーターでは約 6 メガバイトでしたが、(パフォーマンスは 1 パーセント (0.3%) ほど低下したものの)量子化 (int8) によって 4 分の 1 (2.5 メガバイト)にまで縮小できました。
データの増強とデータセットの制限の克服
次に、データセットの問題です。
前回2回目のブログで私は、駐車場画像のデータセットに偏りがあると、駐車場監視AIモデルの学習がうまく進まないこと、駐車場においては主に7つのデータセットの課題があるとお伝えしました。
そこで私は駐車場データの増強やデータセットの制限を克服するために、以下のようなアプローチを試みました。
1. データサンプリング
データ分析において、データセットの中から有意な情報を得るため、データの一部を抽出することをサンプリングと言います。また、ヒストグラムの棒のことを英語ではbin(ビン)と言いますが、ある抽出データがどのビンに属するのかの定義を決めていきます。
まず、駐車場の画像データを、ビン(bin)に配置します。
駐車場の場合は駐車台数がキーになります。たとえば、車が 0 台の画像用のビンが 1 つ、車が 1 台しかない画像用のビンが 1 つなどと決めていきます。駐車場AIデータのトレーニング中は、これらのビンに配置した画像をランダムに選択しAIに答えさせていきます。
さて、昼と夕方では明るさが違うので、AIにより賢くなってもらうには、これらの状態でのサンプリングも必要になります。そこで私はビンをさらに 駐車台数 ✖ 画像の明るさレベル (平均)、明るい、中間、暗いへと分けました。
こうして(影や車の色の違い <明るい白から黒まで>も存在するため、これだけですべての問題が解決するわけではありませんが)様々な明るさ✖台数の駐車場データを設けることで、トレーニング データをより均等に分散させて、トレーニング中のバイアスを減らすことがAIにより賢くなってもらうために必要です。
2. ランダム化によるデータ増強
特定の駐車台数、特定の明るさのデータが十分にない区間も存在します。こうしたトレーニングデータのバイアスを補い均質化する技術としてランダムパッチがあります。
画像の一部分にランダムなパッチを当てて、ふたをします。こうすると、画像内の車の数が変化しますので、違う台数条件のデータを学習させることができます。
ランダム化には他にも方法がありますが、今回のデータの課題の特性を見ながら、ランダムな明るさの変化と、ランダムなコントラスト変更 (ぼかし、シャープ化)も必要と感じ実施しました。
3. ミラーリング
データ増強の方法にミラーリングというものがあります。画像をランダムな角度に水平方向に反転させ、鏡映しのような画像をつくるのですが、私は今回これも用いてみました。
結果
AIモデルのトレーニングには、過学習(オーバーフィッティング)を減らし、バランスの良い学習でAI モデルの堅牢性を向上させる必要がありますが、以上のアプローチの実施後、現時点のデータセットでのAIモデルの認識パフォーマンスは 99% 以上をマークすることができました。
今後の展開
今回のAI モデルは、FCNN (完全な畳み込みネットワーク) と組み合わせた MobileNet バックボーンを使用しましたが、プログラムサイズがまだかなり大きくて、約 2.5 メガバイトでした。 (ただしARM M7 Cortex で MobileNet モデルを実行することは可能です)
プログラムサイズに関しては、Mobilenet バックボーンの削除+完全にカスタム化された AI モデルの作成を行うこと、そしてNeural Architecture Search(NAS)を使ってニューラルネットワークの構造自体を最適化すれば1 メガバイト未満のモデルも構築できると想定しています。
それより重い課題は主な課題はトレーニング データです。 現在のデータセットはおそらく小さすぎて、AI モデルをゼロからトレーニングできません。費用と時間がそれなりにかけて、より多くのデータを収集していく方法は当然ありますが、予算や時間が限られる研究者も大勢いると思います。
だからこそ、私はより高度な AI モデルを使用してトレーニングデータを合成する方法で解決できる可能性に期待しています。大規模なジェネレーティブ AI モデルがトレーニング用データを合成し、その合成データを、今度はIoT やエッジ デバイスで動作する AI モデルのトレーニングに使用するプロセスです。
”合成データは AI データの未来である”
大きなAIがエッジAIのトレーニングをサポートすることが当たり前の世界に1歩でも近づけていきたい。私はこのように強く思っています。
次は、他のエッジAI開発事例についても、お話しできればと思います。